Basic Ruby Web Scraping with Nokogiri
This tutorial will show how to create a simple web scraper using Ruby and the library Nokogiri. Nokogiri (鋸) is the Japanese word for a saw. I presume the library was named as such as it functions as a sort of web saw, slicing up the html of a web page allowing you to extract small chunks with your scraper.
I will use the example of a scraper I made to retrieve the movie listings from my local cinema, the DCA. The aim is to create a script that can retrieve the titles and screening dates of all of the scheduled movies.
Determining the pages to scrape
The first step in creating a scraper is to identify the web pages with the content you wish to retrieve.
Here is a screenshot of the cinema section of the DCA's website.

There are pages for &dquo;This week&dquo;, &dquo;Next week&dquo;, &dquo;26 Dec - 1 Jan&dquo; (two weeks ahead) and &dquo;Coming soon&dquo;.
Some sleuthing of the URLs for each of the pages reveals the following:
- This week - http://www.dca.org.uk/whats-on/films?from=2016-12-12&to=2016-12-19
- Next week - http://www.dca.org.uk/whats-on/films?from=2016-12-19&to=2016-12-26
- 26 Dec - 1 Jan - http://www.dca.org.uk/whats-on/films?from=2016-12-26&to=2017-1-2
- Coming soon - http://www.dca.org.uk/whats-on/films?from=2017-1-2&to=future
Each URL has HTTP GET parameters for the start and end dates with the names &dquo;from&dquo; and &dquo;to&dquo;. The page for movies coming soon simply uses the value &dquo;future&dquo; to show all remaning movie listings.
It looks like if we use Monday's date as the &dquo;from&dquo; parameter and &dquo;future&dquo; as the &dquo;to&dquo; parameter we will retrieve a page with all of the movie listings sceduled from this week onwards. Sure enough a quick test proves this is indeed the case.
Installing Nokogiri
Nokogiri may be installed using the same method as any other Ruby Gem:gem install nokogiriWe can then use Nokogiri by requiring it at the top of our script:
require 'nokogiri'Coding the scraper
Let's take a look at the URL we want to scrape:
allMoviesURL = "http://www.dca.org.uk/whats-on/films?from=#{monday.strftime("%Y-%m-%d")}&to=future"where monday is the date of the start of the current week (see the full source
Now we can retrieve the page using Nokogiri:
page = Nokogiri::HTML(open(allMoviesURL))By inspecting the web pages DOM structure using our browser we can see that each movie is contained in a div with the class &dquo;event&dquo;. We can extract a list of these nodes using Nokogiri's .css() method which accepts a string representing a css selector as an argument:


movieListingNodes = page.css('.event')Those familiar with jQuery will recognise the similarity to selecting DOM nodes using the jQuery object with a css selector in JavaScript e.g.
$('.event')Going back to the inspector we can hover over each piece of information we wish to extract and construct a css selector to retrieve this from the event nodes.
We then encapsulate these extractions into a function for parsing a movie listing node into a data structure:
def parseMovie(movieListingNode)
titleNode = movieListingNode.css('.info')
directorNode = movieListingNode.css('.subheading')
dateNode = movieListingNode.css('.date')
title = titleNode[0].text
title.strip!
title = title.sub(/
(.*)/, '')
director = directorNode[0].text
date = dateNode[0].text
return MovieListing.new(title, director, date)
end
We can then parse all of the listings and print them to the terminal:
movieListings = []
movieListingNodes.each { |movieListingNode| movieListings << parseMovie(movieListingNode) }
movieListings.each { |movieListing| puts movieListing }Running the scraper
Running the scraper yields the following output:

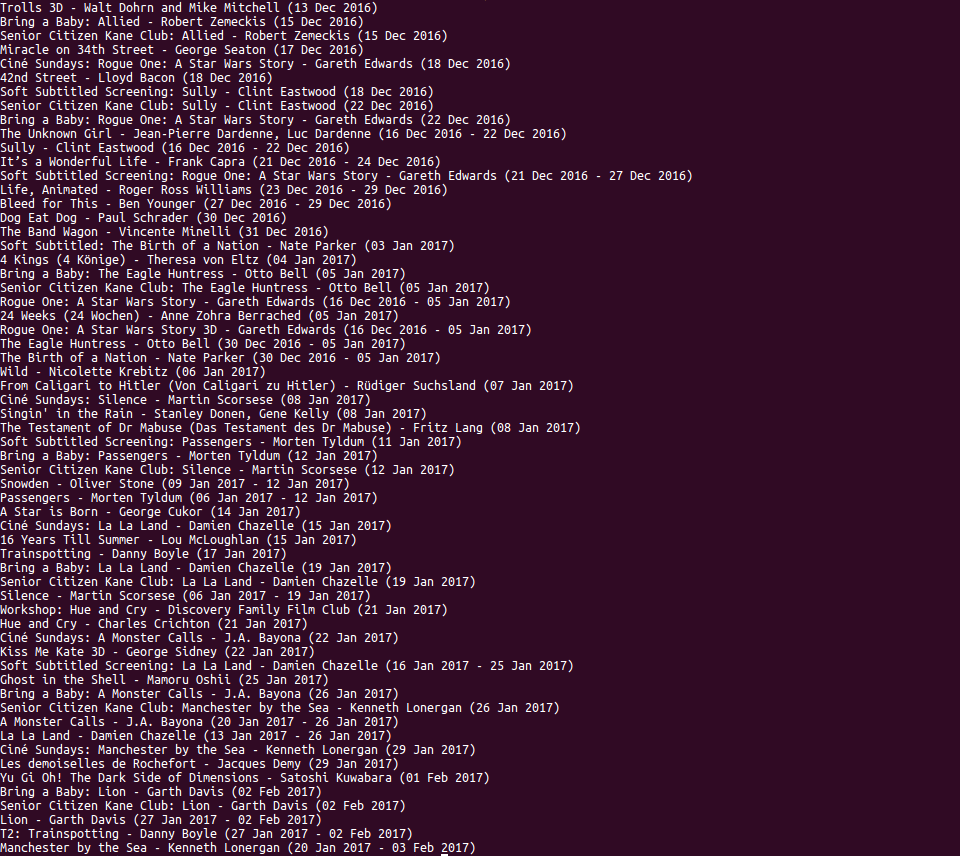
From the list it looks like I'll be seeing Rogue One and couldn't pass up the opportunity to see the original Ghost in the Shell on the big screen!
Conclusion
This post has shown a basic workflow for creating a web scraper.
- Identify the pages with the data you wish to retrieve.
- Use the browser's inspector to determine the location of the data within the DOM.
- Create CSS selectors that represent the desired nodes.
- Use the CSS selectors to scrape the data.
The full code for the scraper is located on my Github account.